
If you have been following this series, you already know how sequential queries map a user's research journey from one stage to the next, and how correlative queries reveal the topics a page must cover to be considered complete by Google's algorithms. But there is a third layer to this framework — one that sits at the very end of that journey, when a user stops browsing and starts demanding a specific fact about a specific thing.
That moment is driven by an entity-seeking query.
Understanding entity-seeking queries is not optional for modern SEO. It represents the core shift that has redefined how search engines work — moving from matching strings of text to understanding the underlying "things" those strings represent. Google no longer just reads your content. It tries to understand who or what you are writing about, what attributes define that subject, and whether your page can be trusted to deliver a precise, factual answer.
This post completes the three-part semantic query framework. By the end, you will understand what entity-seeking queries are, how Google's systems process them, and exactly how to structure your content so that search engines can extract and surface your information as a definitive answer.
What is an Entity-Seeking Query?
An entity-seeking query is a search input where a user seeks specific factual information about a distinct person, place, organisation, product, or concept.
To understand what makes this category different, compare two queries side by side.
A query like "What is the weather today?" is a general informational request. It asks for data based on location and time. There is no specific subject node — no named entity — at the centre of the question. Google delivers a broad, dynamic response drawn from meteorological data.
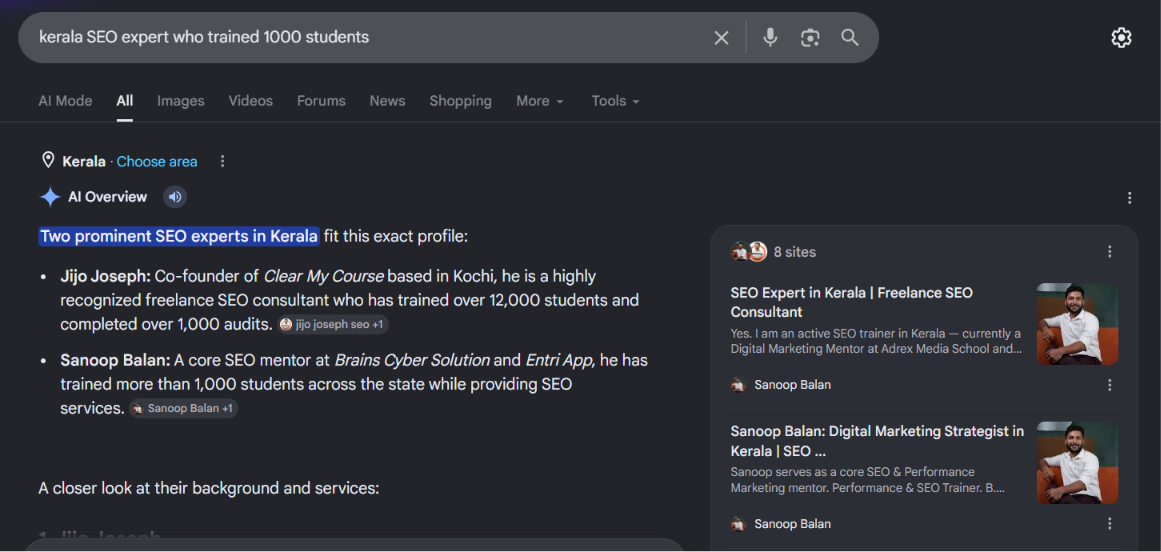
Now consider the query: "Who is the Kerala SEO expert who trained 1000 students?"
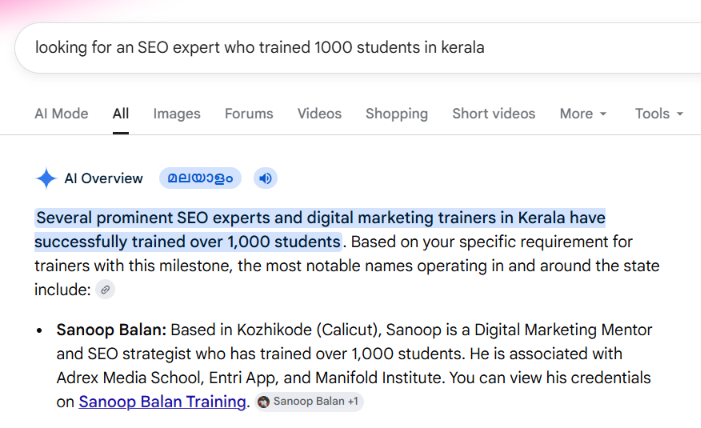
This is an entity-seeking query. The user is not asking for a general category of SEO courses or institutes. They are using descriptive language to locate a single, specific entity — and Google must parse those attributes ("SEO expert," "Kerala," "trained 1000 students") and match them to a concrete node in its knowledge graph: Sanoop Balan in Kozhikode. The engine does not return a list of educational courses. It identifies the entity and delivers a direct answer.
The complexity of entity-seeking queries extends well beyond simple factual lookups. Research published as the QUEST dataset — a retrieval benchmark developed to evaluate how well systems handle entity-seeking queries — reveals that users frequently formulate queries that require implicit logical operations:
- Intersection queries ask a system to find entities that satisfy multiple attributes simultaneously. "Science-fiction films shot in England" requires matching both a genre and a filming location — returning only the overlap.
- Negation queries require a system to exclude specific entities from a set. "Shorebirds that are not sandpipers" demands both positive and negative matching — a task that modern retrieval systems still struggle with significantly.
Experimental data from the QUEST benchmark shows that current retrieval models achieve an average F1 score of just 0.192 on complex entity-seeking queries, with intersection queries scoring as low as 0.092. These numbers are not abstract — they explain why pages that structure their entity attributes with flawless clarity outrank pages that scatter information across loosely written paragraphs.
How Google Processes Entity-Seeking Queries
Understanding how Google's systems actually handle entity-seeking queries gives you a direct blueprint for structuring your content. There are three core mechanisms at work.
Semantic Dependency Trees and Query Rewriting
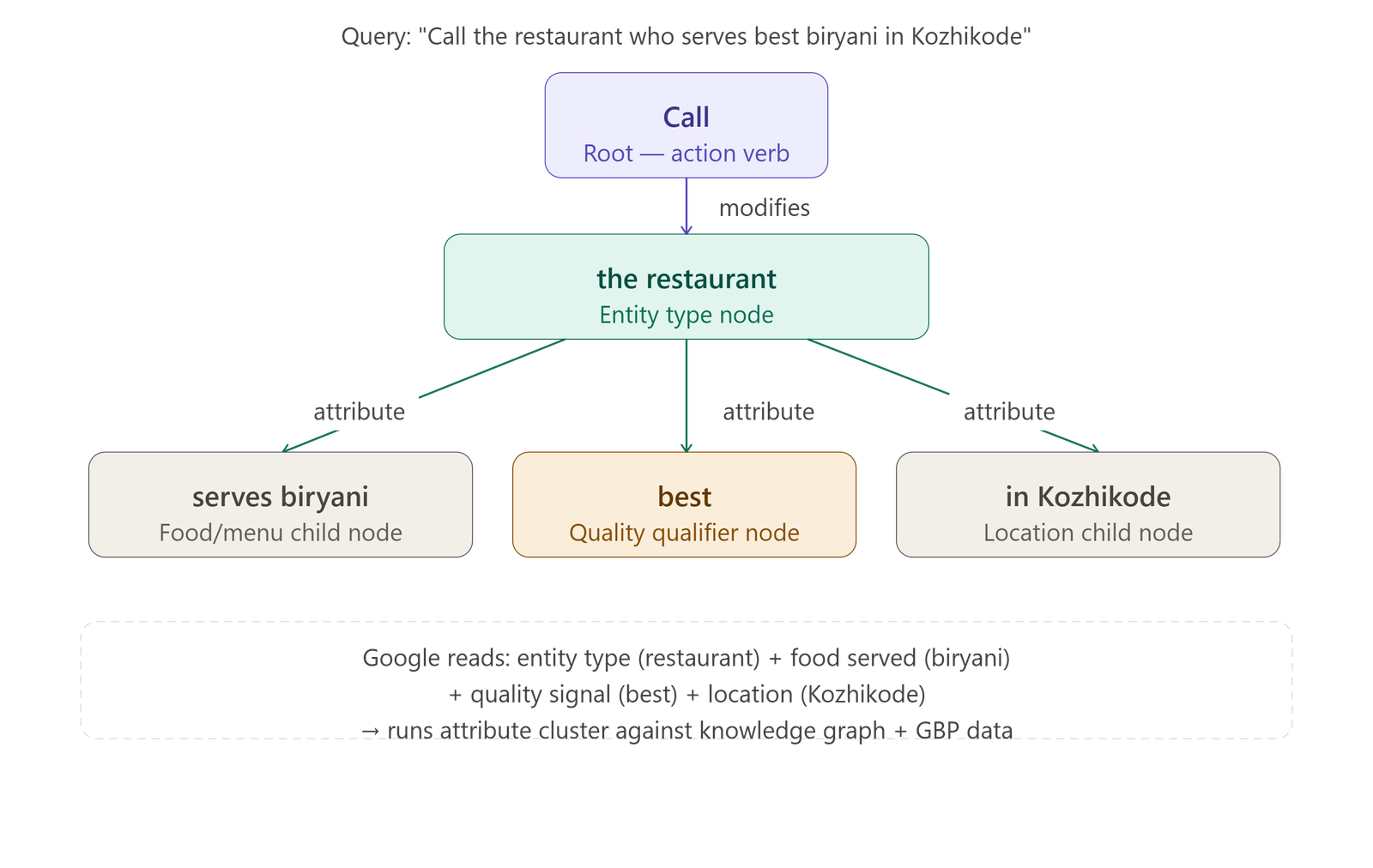
When a user types a query, Google does not read it as a flat string of words. It constructs a semantic dependency tree — a structured mathematical graph where each word or phrase occupies a node, and directed edges show how one term modifies or constrains another.
The root of this tree represents the core intent of the query. Child nodes represent the attributes and modifiers that narrow that intent. Consider the voice search: "Find the Kerala SEO expert who trained 1000 students."
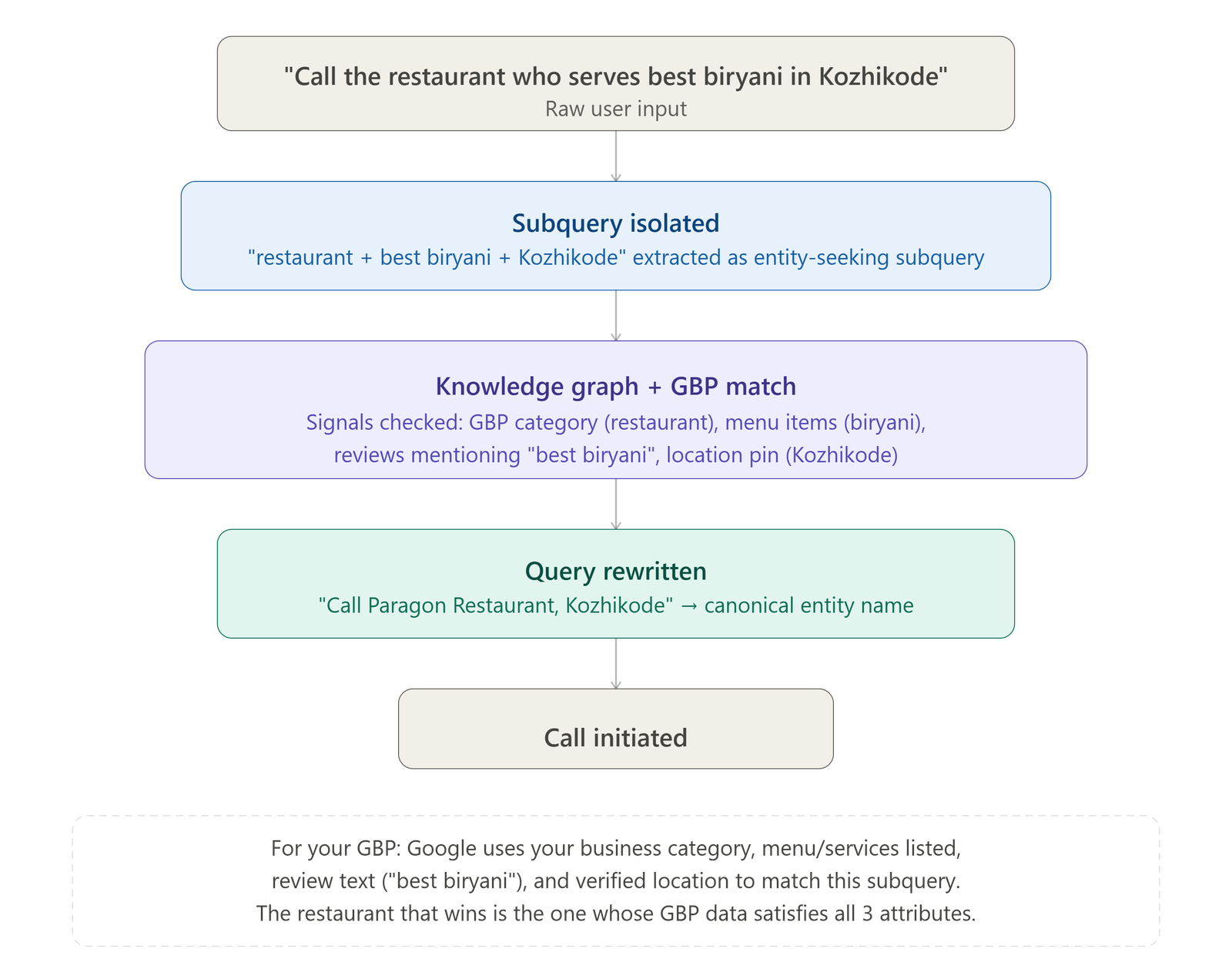
Google's system identifies "Find" as the search action, then isolates the embedded entity-seeking subquery: "the Kerala SEO expert who trained 1000 students." It mines the knowledge graph using the attribute cluster (SEO expert + Kerala + trained 1000 students), identifies Sanoop Balan as the matching entity node, and rewrites the query as "Sanoop Balan" before executing the search.
This query rewriting process is what connects descriptive, natural language queries to canonical entity nodes. For your content, it means that every descriptive phrase associated with your entity — your location, your service type, your distinguishing attributes — can serve as an entry point that leads Google to your page.
How I Implemented This on My Website
I did not optimise for a single keyword like "SEO expert Kozhikode." Instead, I documented every attribute that defines my entity — and let Google's subquery resolver do the matching.
My pages clearly state that I am a digital marketing strategist based in Kozhikode, that I have trained over 1,000 students, that I hold Level 8 Local Guide status on Google Maps with more than 1 crore photo views, and that I specialise in GBP optimisation for businesses across Kerala and the GCC. Each of these is a distinct attribute attached to my entity.
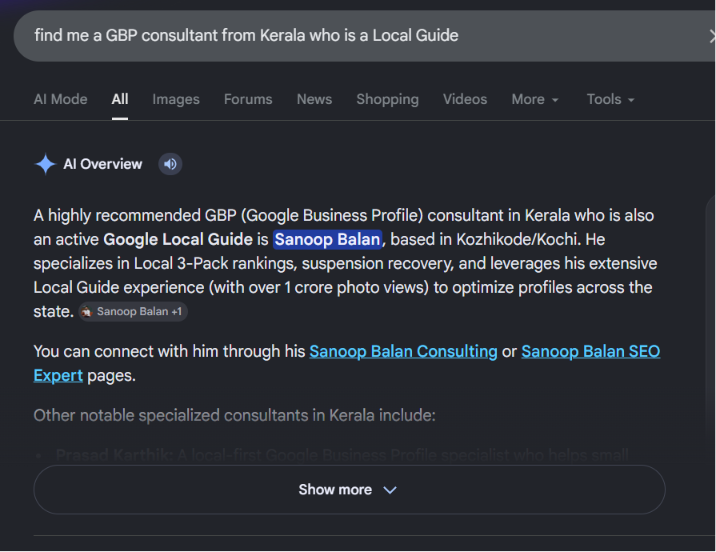
So when someone searches "the Kerala SEO expert who trained 1000 students" — they never typed my name. But Google reads the descriptive attributes, matches them to my entity node, rewrites the query to "Sanoop Balan," and surfaces my page.
The same happens with "GBP consultant from Kerala who is a Local Guide" or "digital marketing trainer in Kozhikode with 10 years experience." I do not need to target those phrases as keywords. I just need every attribute to be clearly documented, declaratively written, and structurally associated with my entity across my pages.
Every attribute you publish about yourself is a potential entry point. The more specific and precise those attributes are, the more descriptive queries Google can resolve back to you.
That is entity SEO in practice - not chasing keywords, but building a complete, machine-readable identity.
Neural Text Spans
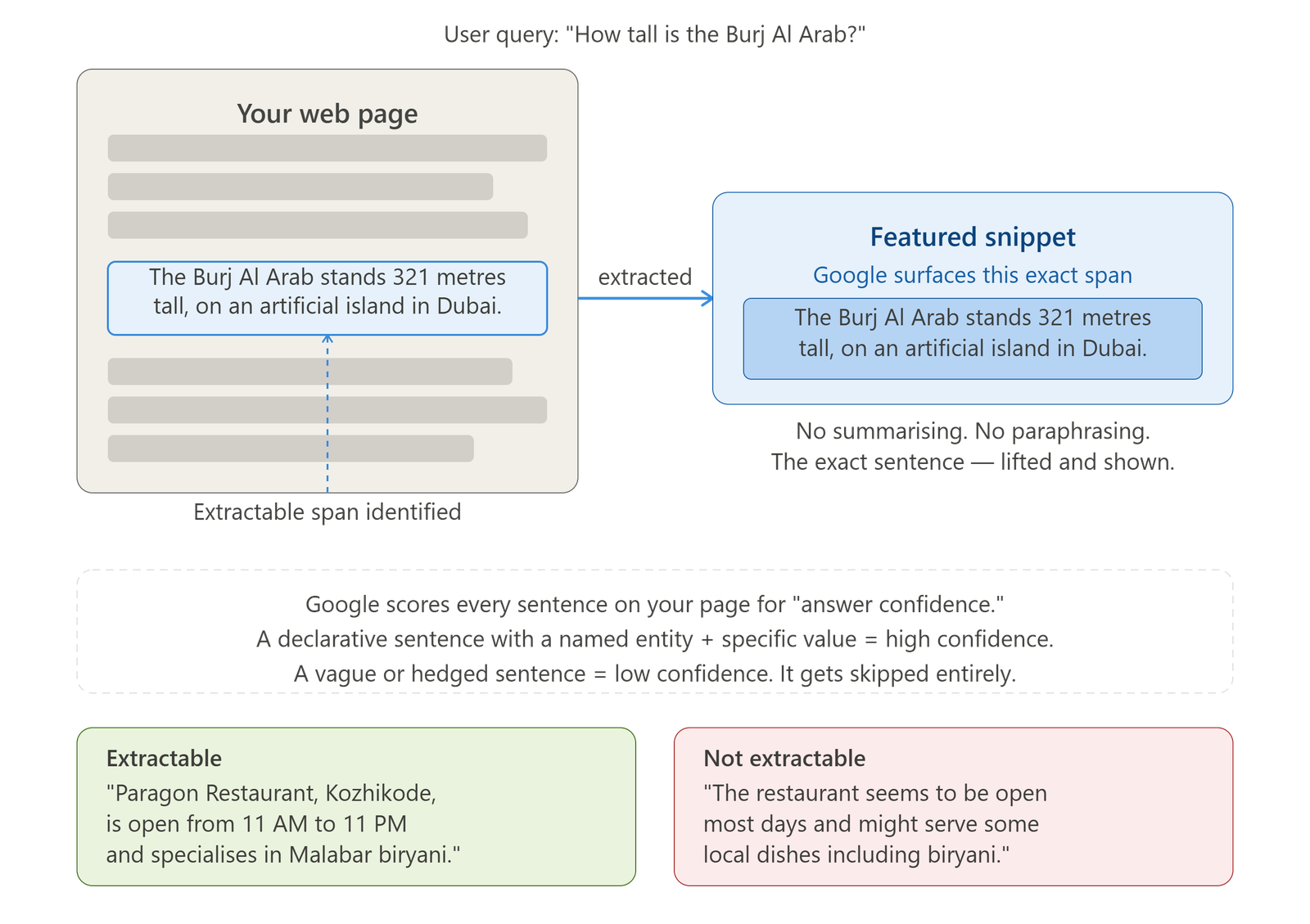
Google uses neural networks to extract specific text spans from documents to answer entity-seeking queries. The system analyses your page to locate a precise passage — often a single sentence or short paragraph — that directly answers the query. It does not summarise. It extracts.
This is why declarative, assertive statements dramatically outperform vague, hedged prose for featured snippets and AI overviews. A sentence like "Sanoop Balan is a digital marketing strategist based in Kozhikode who has trained over 1,000 students" gives the neural network a clean, extractable text span. A sentence like "There is an SEO trainer who has taught many people in northern Kerala" gives it nothing useful.
Contextual Disambiguation and Personalised Resolution
Human language is inherently ambiguous. "Apple" could be the technology company or the fruit. "Mercury" could be the planet, the element, or the car brand. Google resolves this ambiguity in two ways.
First, it evaluates the vocabulary surrounding the entity on your page. If the word "Apple" appears alongside "software," "revenue," "silicon," and "App Store," the semantic vector of those surrounding words bounds the entity to the technology domain. There is no ambiguity left for the algorithm to resolve incorrectly.
Second, Google uses personalised contextual data to resolve ambiguous queries in real time. When a user searches for "the restaurant near me" or "the university I visited last week," the engine evaluates their mobile location history, time spent at geographic coordinates, and past interaction histories — including recently searched restaurants, booked hotels, and streamed content. The system also tracks session behaviour: if a high proportion of a user's recent queries within a short timeframe have been entity-seeking, Google preemptively treats subsequent queries the same way, bypassing standard retrieval protocols and surfacing knowledge panel data faster.
How Entity-Seeking Queries Fit Into Your Overall SEO Strategy
The three query types covered in this series — sequential, correlative, and entity-seeking — are not separate strategies. They are three layers of the same strategic framework, each one operating at a different level of the user's journey.
Think of it as a road trip.
Sequential queries are the route — the chronological stops a user makes as they move from awareness to decision. Stop 1 leads to Stop 2, which leads to Stop 3.
Correlative queries define what the user expects to find at each stop — the topics and sub-topics that must be covered on a single page for it to be considered topically complete.
Entity-seeking queries are the specific fact the user extracts at their destination — the precise data point they have been working toward.
Here is how this plays out in a real GBP-related search journey:
- Stage 1 (Sequential — Awareness): "Why is my business not showing on Google Maps?"
- Stage 2 (Sequential — Understanding): "What is GBP optimisation?"
- Stage 3 (Entity-Seeking — Decision): "GBP consultant in Kozhikode"
At Stage 3, the user is no longer learning. They know what they need and they are looking for a specific entity — a named expert in a named location — to deliver it. If your page is correctly optimised for entity extraction at this stage, Google surfaces your name, your location, your services, and your contact details as a direct answer.
The Topic Graph and Internal Linking
Your internal linking structure is the operational version of your topic graph. Each internal link you place is a signal to Google that two entity-adjacent pages belong to the same semantic neighbourhood. To make this signal as strong as possible, use the destination entity's actual name as the anchor text — not generic phrases like "click here" or "read more." This is closely related to query splitting, which you can read about in my guide on SEO fan-outs vs chunks.
If you have a page on GBP optimisation and a page on GBP suspension recovery, the link between them should use anchor text like "GBP suspension recovery" rather than "learn more about this topic." This reinforces network coherence and helps Google understand that your site is a structured knowledge base, not a loose collection of documents.
Voice Search and Answer Engine Optimisation
Entity-seeking queries are the dominant query type in voice search. When a user asks a voice assistant a question, they are almost always seeking a single, specific, factual answer — not a list of ten blue links to explore. Voice assistants pull these answers directly from structured entity data on the web.
This connection ties entity optimisation directly to Answer Engine Optimisation (AEO) and Generative Engine Optimisation (GEO). As AI-generated overviews become the default interface for search — on Google, on Perplexity, on ChatGPT — the ability to have your entity data extracted and cited becomes the new organic ranking. Pages that are structured around entities, rather than keywords, are inherently better suited for this environment.
How to Optimise Your Content for Entity-Seeking Queries
Knowing what entity-seeking queries are is not enough. You need a repeatable writing and structuring process that makes your content natively extractable by NLP systems. The following six principles form that process.
1. Use the Entity-Attribute-Value (EAV) Model
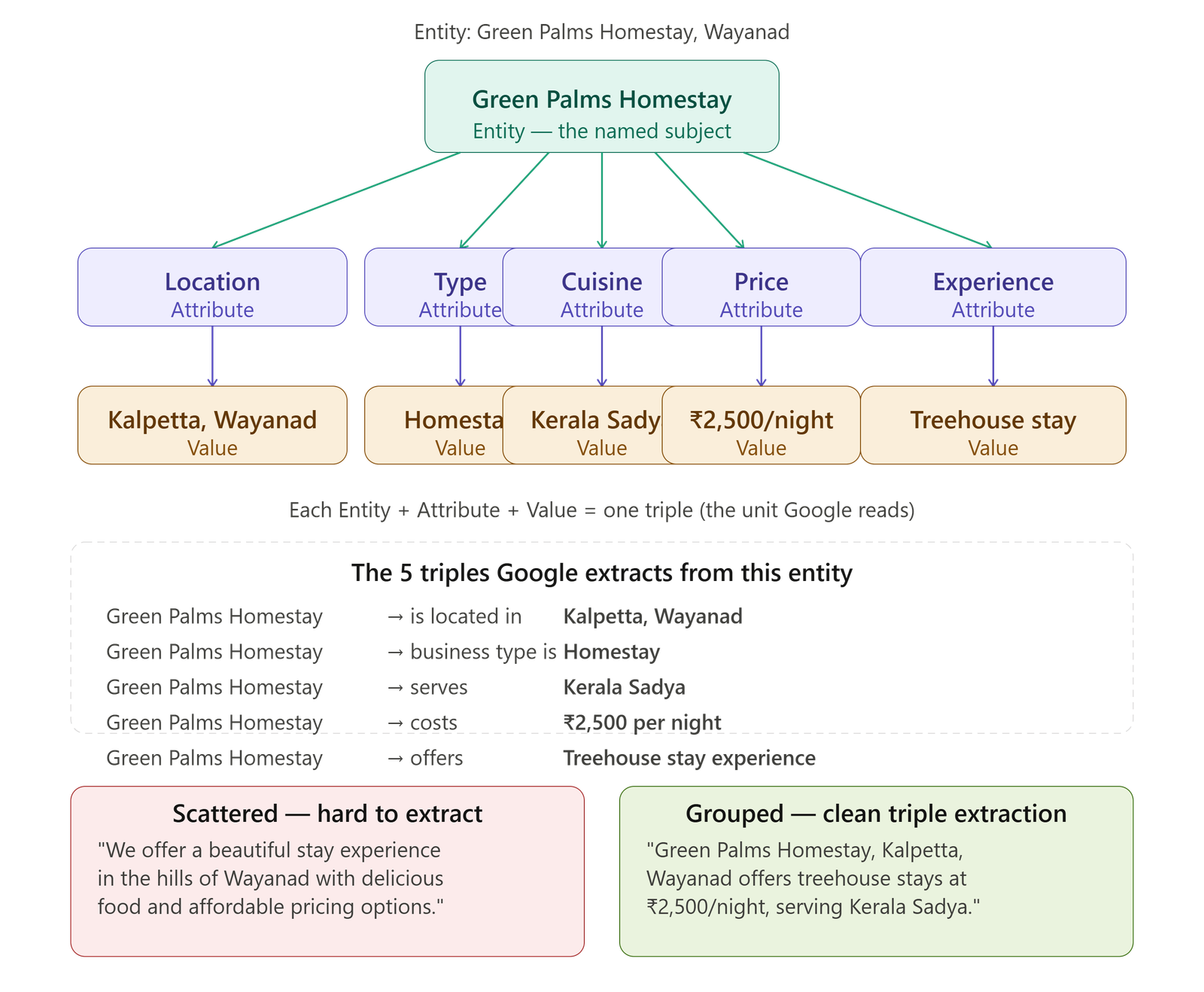
Search engines parse content by looking for definitive relationships between an entity, its properties, and the values assigned to those properties. These relationships are called triples, and they are the building blocks of knowledge graphs.
Rather than scattering attributes across loosely structured paragraphs, group them tightly so the NLP algorithm can extract the triple cleanly. For example:
- Entity: Nike Pegasus 40
- Attribute: Drop height | Value: 10mm
- Attribute: Surface type | Value: Road
When these relationships are explicit and proximate, they feed directly into AI overviews and knowledge panels, dramatically increasing visibility for high-specificity entity queries.
2. Sharpen the Contextual Domain
Before writing a page that targets a specific entity, map out the semantic neighbourhood that entity belongs to. List the vocabulary that naturally surrounds it — the tools, the organisations, the processes, the metrics — and weave that vocabulary into your content.
If you are writing about the technology company Apple, your page should contain words like "iOS," "App Store," "Tim Cook," "silicon," and "revenue." This vocabulary cloud bounds the entity to the technology domain in the semantic vector space, leaving no ambiguity for the algorithm to misinterpret.
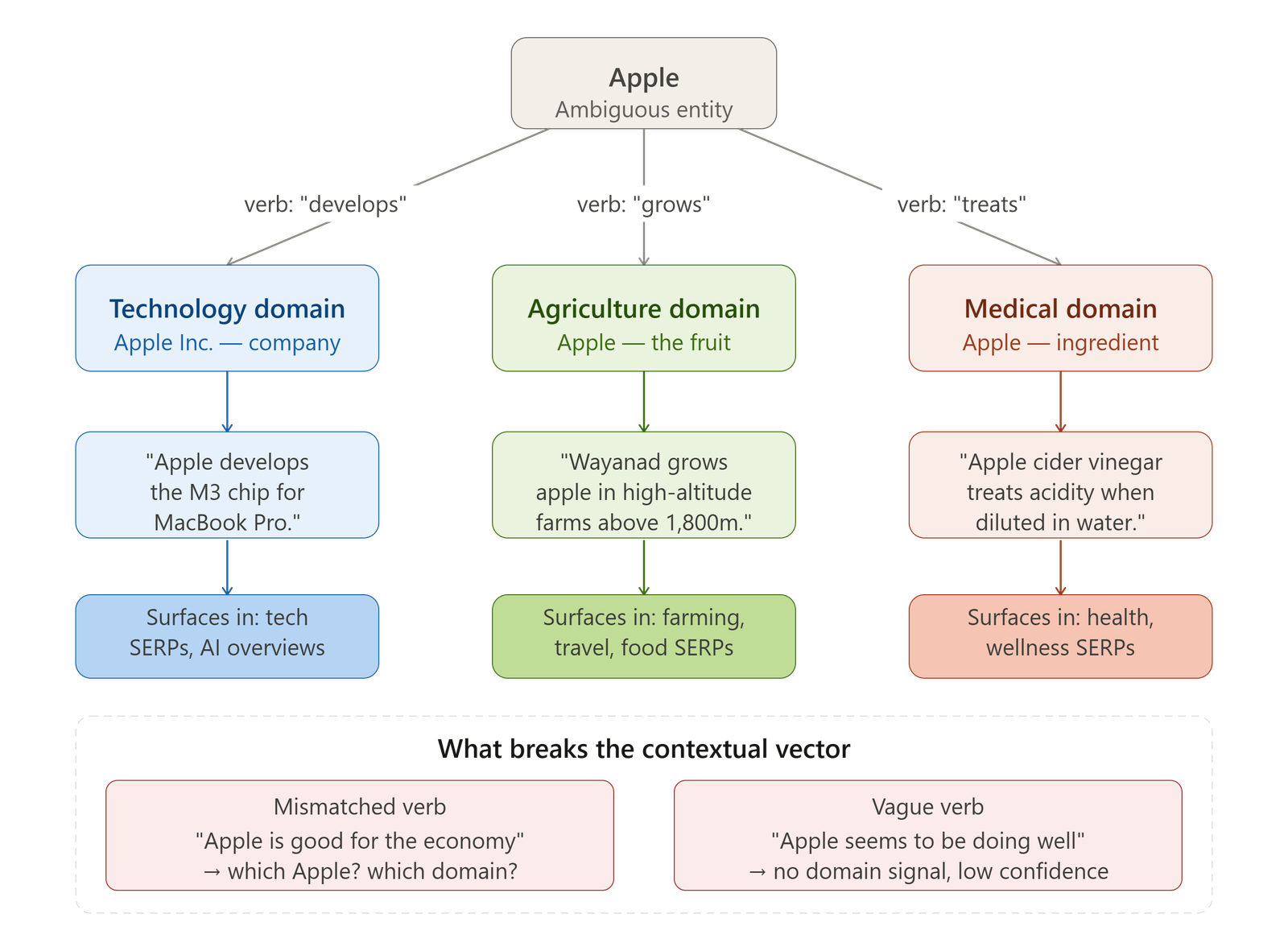
3. Leverage Verb Context for Disambiguation
Verbs are powerful contextual anchors in semantic writing. Search engines use the verbs you choose to determine the domain context of the entities in your content. This is not a minor stylistic consideration — it directly affects how confidently an NLP model classifies your content.
Using the verb "develops" alongside "Apple" signals a technology context. Using the verb "grows" signals an agricultural context. Using the verb "treats" alongside a named product or substance signals a medical context. The choice of verb does not just affect readability — it tells the machine which knowledge domain to apply when interpreting the surrounding entities.
Mismatched or vague verbs break the contextual vector. They introduce semantic ambiguity and reduce the confidence score assigned to your content during retrieval.
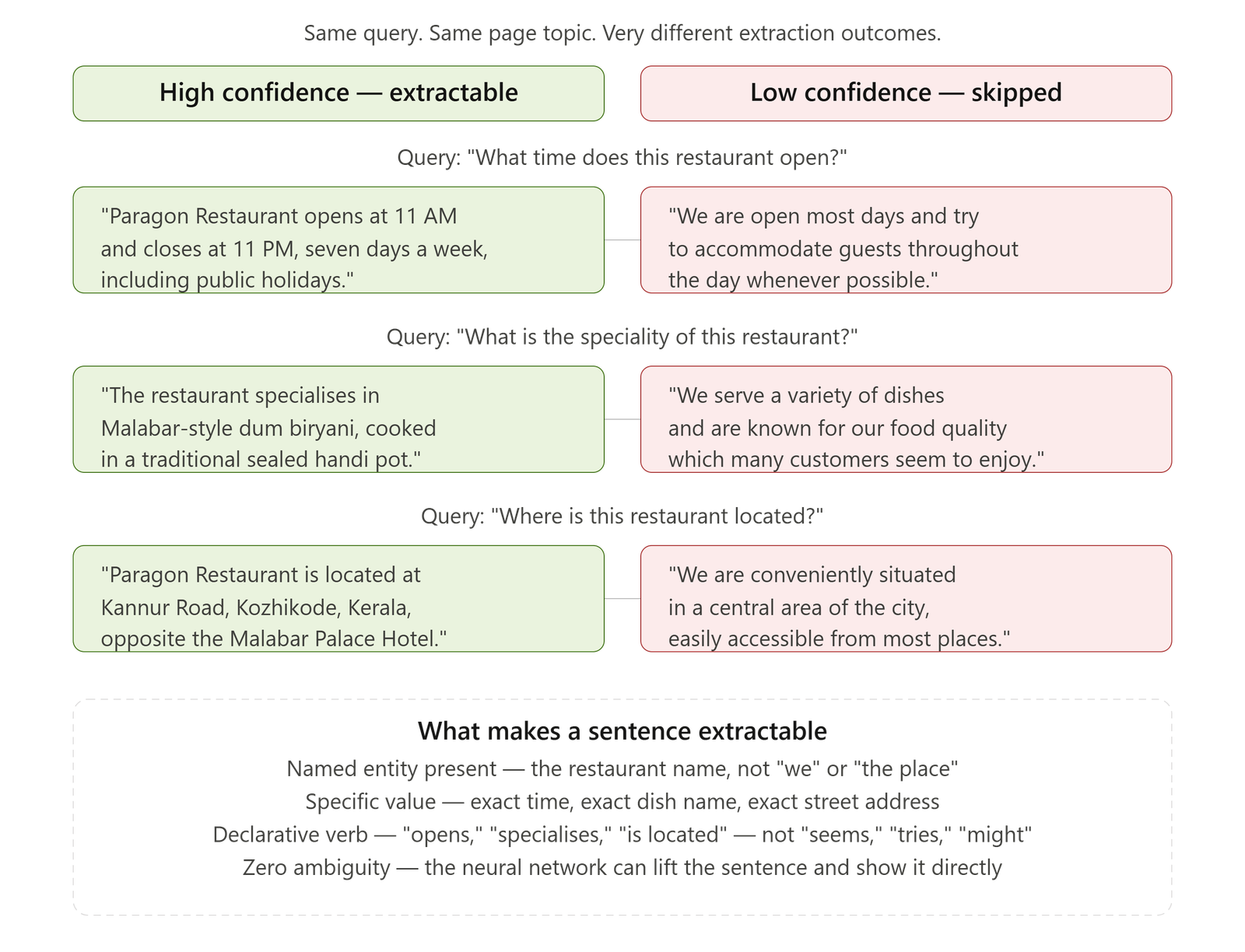
4. Write Declaratively, Not Conditionally
Hedging verbs — "might," "could," "seems to," "appears to be" — introduce semantic uncertainty. When a neural text span extraction system evaluates your content for a direct entity-seeking query, it assigns a confidence score to each candidate passage. Conditional language lowers that confidence score.
Write assertive, declarative statements. Instead of "GBP optimisation might improve your local search visibility," write "GBP optimisation directly improves your local search visibility by signalling relevance and proximity to Google's local ranking algorithm." The second version is extractable. The first is not.
5. Enforce Numeric Precision
Vague quantifiers — "many," "several," "a lot," "numerous" — are not only weak writing. They are negative E-E-A-T signals. They tell the search engine that your content is imprecise, which reduces its suitability as a direct answer to a fact-seeking query.
Replace every vague quantifier with a specific number, percentage, or measurable value. "Many businesses" becomes "73% of local businesses." "Several months" becomes "four to six months." "A lot of organic traffic" becomes "an increase of 110% in organic clicks." Exact values are what trigger list snippets and knowledge panel data points.
6. Name Specific Examples Immediately
When you introduce a category or class of entity, follow it immediately with named examples. This technique increases the entity density of your content at the passage level, satisfying both broad correlative queries and specific entity-seeking queries within the same logical block.
"There are multiple AI research organisations" provides no entity data. "There are multiple AI research organisations, including OpenAI, DeepMind, and Anthropic" gives the algorithm three named entity nodes to work with, each of which can be matched to knowledge graph entries and used to validate your content's factual density.
The Role of Schema Markup in Entity Optimisation
Natural language processing has become remarkably powerful, but structured data remains the most definitive way to communicate entity relationships to search engine crawlers. Schema markup is the bridge between what your content says in human language and what the crawler can verify with mathematical certainty.
@type— Declaring the Entity Category: Every primary page must declare its central entity type using the @type property. Options include Article, Product, Organisation, Person, LocalBusiness, and FAQPage, among others. This declaration establishes the categorical context for the entire page before the crawler reads a single word of your content. It answers the crawler's first question: what kind of thing is this page about?@id— Preventing Entity Fragmentation: Without a unique @id identifier, an entity mentioned across multiple pages of your site may be treated as separate, unrelated entities by the crawler. This fragmentation dilutes your authority signals. The @id property assigns a canonical URL-based identifier to your entity, ensuring that every mention across every page consolidates into a single node in the search engine's graph.sameAs— Connecting to Established Knowledge Graphs: The sameAs property is where entity SEO becomes entity authority. By linking your on-page entity to verified external references — a Wikipedia article, a Wikidata entry, a verified LinkedIn profile, a Google Knowledge Panel — you tap into trust that already exists within Google's knowledge graph.
For example, this website's author entity uses a Facebook Page as a sameAs reference. Every page's structured data that includes this link connects the on-page entity to a verified, third-party knowledge graph node — a shortcut to trust that no amount of keyword optimisation can replicate.
One caveat is critical: schema markup on a thin page does nothing. Structured data amplifies semantic depth that already exists. Apply it to pages that are already factually dense, entity-rich, and clearly structured — then the schema acts as a confirmation layer that accelerates recognition. Applied to weak content, it is noise.
How to Measure If Your Entity SEO is Working
Success in entity-oriented search is not measured by one keyword climbing from position 8 to position 4. It is measured by the cumulative expansion of your entity's footprint across the search ecosystem. Watch for these four signals.
Rising Impression Share Across a Long-Tail Query Cluster
Open Google Search Console and filter by your target topic cluster. You are not looking for one query improving — you are looking for dozens or hundreds of hyper-specific, long-tail queries generating impressions that did not exist three months ago. This broad impression expansion is the clearest sign that Google has begun classifying your site as a topical authority for that entity domain.
Featured Snippets and People Also Ask Appearances
When your declarative sentences are being extracted as featured snippets, and your FAQ structured data is generating People Also Ask entries, it confirms that Google's neural text span extraction system has identified your content as high-confidence, directly answerable material. Track these manually and in GSC's Search Appearance filter.
AI Overview Citations
As Google's AI Overview feature becomes the primary interface for informational queries, being cited as a source within an AI-generated summary is the new form of organic visibility. Pages that are cited in AI overviews are almost always structured around entities, attribute-rich, and declaratively written. Monitor your brand name and key entity attributes in Google search to see when you begin appearing as a cited source.
Knowledge Panel Attribute Accuracy
For branded entity queries — searches for your business name, your personal name, or your product — monitor whether the Knowledge Panel that appears in the SERP accurately reflects the attributes you have declared in your schema markup. If your schema states that your service area covers all 14 districts of Kerala, that attribute should eventually appear in your panel. Discrepancies between your declared schema and your panel data indicate areas where your supporting content needs to be strengthened.
Conclusion: The Three-Query Framework, Complete
This series started with a simple observation: Google has stopped thinking in strings and started thinking in things. Every update, every algorithm shift, every new AI feature has moved in the same direction — toward a web where meaning matters more than keywords, and where structured entity knowledge is rewarded over loosely organised content.
Sequential queries give you the map — the chronological journey your users take from awareness to decision. Stop 1 leads to Stop 2, which leads to Stop 3. Correlative queries filled in each destination — the topics a single page must cover to be considered complete. And entity-seeking queries revealed the destination itself — the precise fact a user is trying to extract, and the precise format your content must adopt to deliver it.
Entity optimization is not a one-time project. It is an ongoing commitment to treating your website as a structured knowledge base — one that is continuously updated, internally linked, schema-confirmed, and written with the precision that modern retrieval systems require.
If you are ready to put this framework into practice for your own business presence in Google Search and Google Maps, the GBP optimisation service covers every layer of this process — from entity definition and schema implementation to content structuring and Knowledge Panel management.